
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- pmf
- 통계학입문
- 균일분포
- 표본평균
- 피어슨상관계수
- 사조사
- 베르누이분포
- Anaconda
- 수치형자료
- 포아송분포
- 수학적확률
- 행사다리꼴
- 이변량자료
- 조건부확률
- 이산형
- 이항분포
- 통계학개론
- 확률밀도함수
- 연속확률변수
- 절삭평균
- 누적분포함수
- 모수
- 기본행연산
- 표본공간
- 이산확률질량함수
- 모평균
- 기댓값과 분산
- 범주형자료
- jupyter notebook
- 첨가행렬
- Today
- Total
Syeonny의 블로그
자연어처리 (5) 출력값 생성기법 본문
https://www.boostcourse.org/ai330/lecture/1455757?isDesc=false
자연어 처리의 모든 것
부스트코스 무료 강의
www.boostcourse.org
decoding 출력값 생성 기법
greedy decoding
test time에서 순차적으로 실행
전체가 아닌 가장 높은 확률을 가지는 단어를 택해 decoding 진행
time step 현시점에서 가장 좋아 보이는 단어를 그때그때 선택하여 최적의 score 선택.
만약, 단어를 잘못 생성했다면?
: 최적의 예측값을 생성해 낼 수 없다.
생성을 끝내는 시점. (종료시점)
: 모델의 end token을 생성했을 때
exhaustive search
가능한 모든 경우의 수를 탐색하여 가장 높은 확률을 갖는 시퀀스를 찾는 방식
단어를 하나씩 생성하여 확률값 순차적으로 곱함
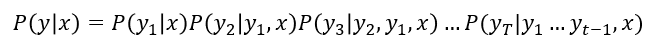
출력 y 입력 x
P(y_1|x) y_1에 대한 확률값
가능한 모든 경우의 수를 따짐. 'y의 조합'
시퀀스 길이가 t일때 고를 수 있는 단어의 가짓수 v^t
v^t를 계속 곱하면 너무 많아짐
최적의 결과를 얻을 수 있는 이점이 있지만, 계산량이 매우 크기 때문에 실시간 처리에는 비효율적
Beam search
greedy와 exhaustive search 중간
매 time step 마다 정해놓은 k개의 가짓수 (경우의 수) 만을 고려
마지막까지 decoding을 고려하여 k개 후보 중 확률이 제일 높은 값을 선택
==> 상위 후보만을 유지하며 다음 단어를 생성
*k (beam size) 보통 5~10의 값 선택

- 확률값이 커질수록 log값은 단조증가
각 time step 마다 log 확률을 사용하여 누적된 확률을 계산.
log 값이 단조 증가하므로 확률값이 커질수록 log 값이 커져 큰 가설이 유지
후보의 확률을 계산하여 가장 큰 hypothesis 를 최종 결과물의 예측값으로 선정함
생성을 끝내는 시점
: 서로 다른 경로나 가설이 존재. 각각 다른 token에서 end token 생성. → 그 경로에서 더 이상 생성하지 않음. 결과 임시로 저장 → 나머지는 계속 생성 → 모두 end 이면 중지
완료된 time step 중 확률이 가장 높은 score를 선택함.
그러나
단어가 순차적으로 계속 생성되는 동시사건이기에, 기존 값에 - minus 값을 더함
→ 짧은 sequence는 상대적으로 값이 높고 긴 sequence는 상대적으로 값이 적음
따라서!
각 가설 별 단어 개수로 나누는 평균 확률값을 사용한다.
gpt says.
<< 순차적 확률 곱으로 인해 짧은 시퀀스보다 불리할 수 있으므로, 이를 보정하기 위해 **평균 확률(또는 길이로 나눈 확률)**을 사용합니다. 이는 길이가 긴 후보가 과도하게 불리하지 않도록 하여 공정한 결과를 유도 >>

전체 탐색 없이도 효율적으로 높은 확률의 시퀀스를 생성할 수 있음
BLEU score
Bilingual Evaluation Understudy
생성 모델의 품질 (결과의 정확도) 을 계산하는 척도 ( 정확도와 유사도)
정답 단어의 확률 값이 제일 크도록 or 분류 정확도를 계산함
특정 time step에서 특정 ground truth가 나와야 함
단어를 중간에 하나 빼거나 많이 생성한 경우
평가방법 2가지
- precision
- recall
F-score (조화평균)
N-gram N개의 연속된 값을 이용 - precison 만 사용함.
* N: 1~4 개
why?
번역 태스크에서 정답문장의 몇 단어가 빠져도(재현율이 떨어져도) 문장의 의미가 유사할 수 있지만, 문장에 없는 단어가 오역되어 들어오면(정밀도가 떨어지면) 영향이 큼
단어들의 일치도가 높을지라도 정답문장과 연속적으로 단어가 일치하지 않는다면 BLEU score값이 0이 나올 수도 있다.
(단어 일치율이 높지만 순서가 맞지 않은 경우)


'자연어처리' 카테고리의 다른 글
| 자연어처리 (7) GPT와 BERT (0) | 2024.11.11 |
|---|---|
| 자연어처리 (6) transformer (1) | 2024.11.09 |
| 자연어처리 (4) seq2seq with attention (2) | 2024.10.24 |
| 자연어처리 (3) RNN (0) | 2024.10.15 |
| 자연어처리 (2) w2v & glove (2) | 2024.09.30 |



